
Original paper: Nanoparticle elasticity directs tumor uptake
In my previous post on soft nanoparticles, you were introduced to polymer-based nanoparticles that could be used in biomedical applications, one of which is cancer therapy. These nanoparticles have a range of useful properties for cancer treatments, including their spherical shape and small size (~100 nm), both of which are similar to exosomes, small globules that are used in nature for transferring proteins between cells. Since cells naturally absorb exosomes, artificial particles with this size and shape should also be easy for cells to absorb, which means these particles could be used to deliver drugs into cells. While this idea sounds promising, it hasn’t worked out in practice — when drug-loaded polymer-based nanoparticles were injected into a tumor, subsequent tests showed that less than 1% of the injected dose entered the cancer cells. Since these particles were the correct size and shape, why didn’t they get inside the target cells?
One possibility is that the elasticity (or stiffness) of nanoparticles is to blame: scientists have suspected that this mechanical property can affect the ability of nanoparticles to squeeze themselves through the cell’s membrane. Unfortunately, it is difficult to test this hypothesis directly, because modifying the elastic properties of a nanoparticle generally requires modifying its chemical properties as well. To solve this problem, Peng Guo and coworkers designed a special kind of nano-objects — spherical nanolipogels — with tunable elasticity. In this paper, they proved for the first time that breast cancer cells take up soft, squishy particles more easily than they take up hard ones.
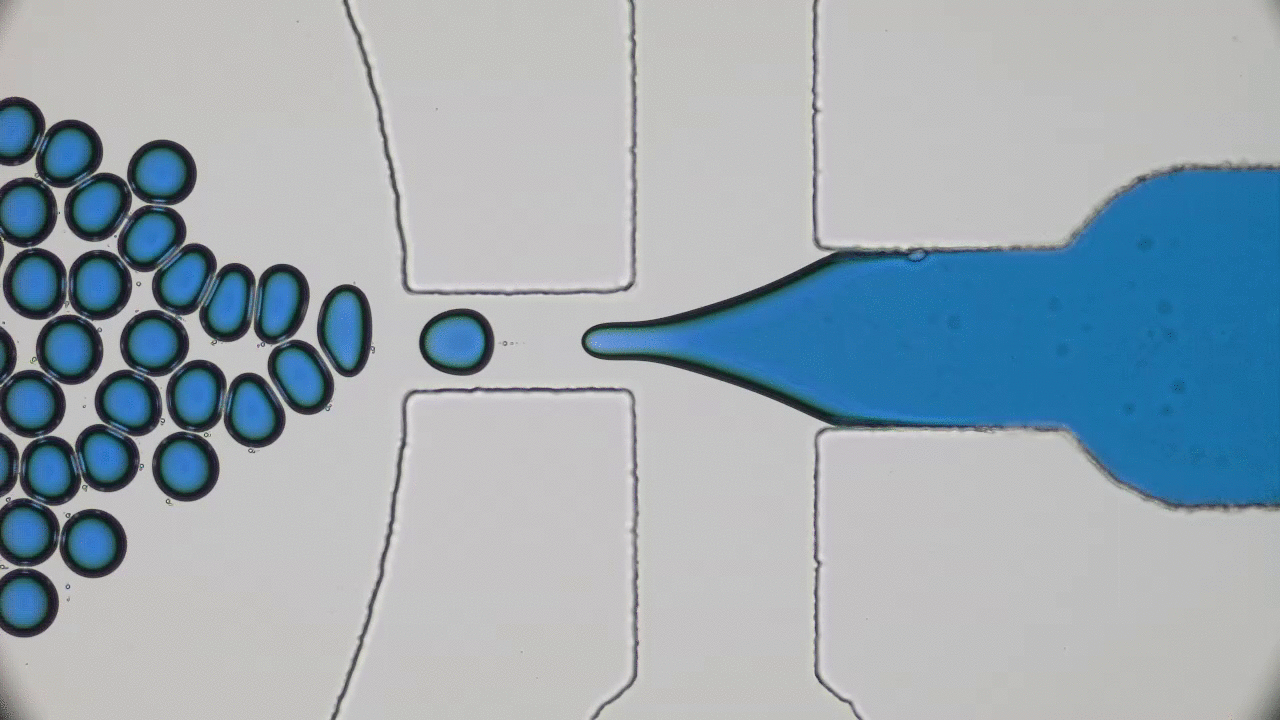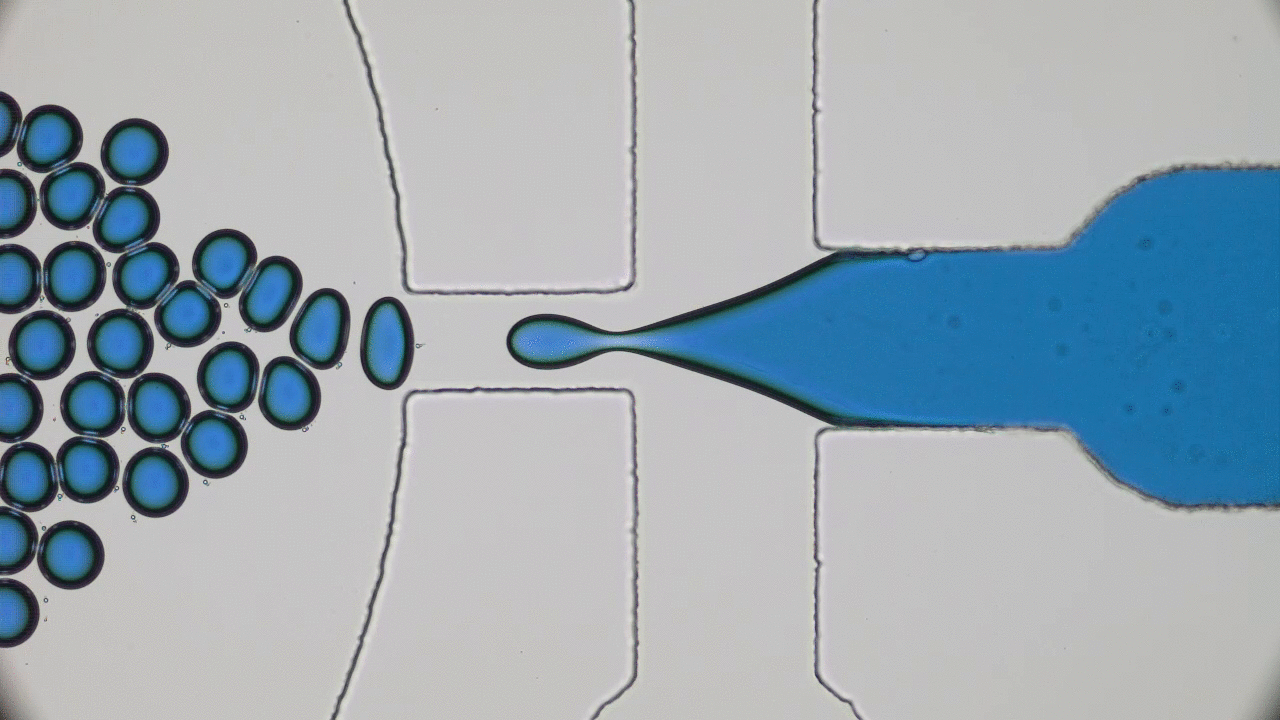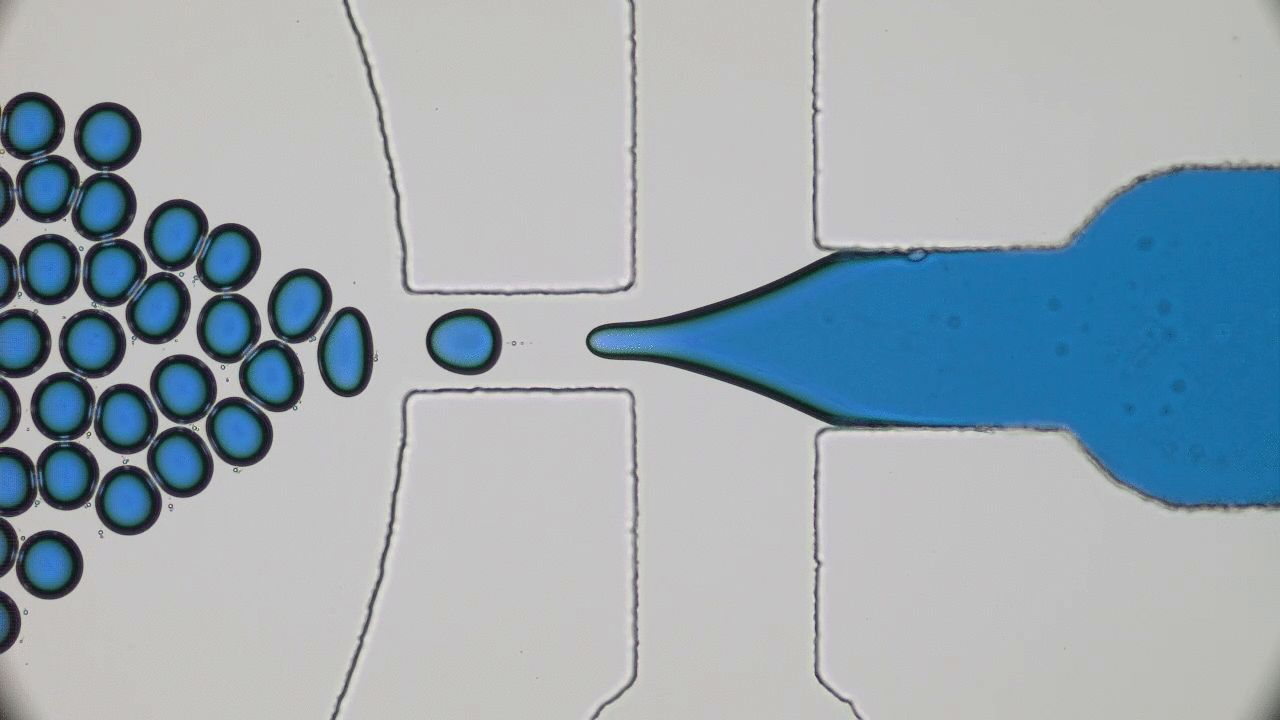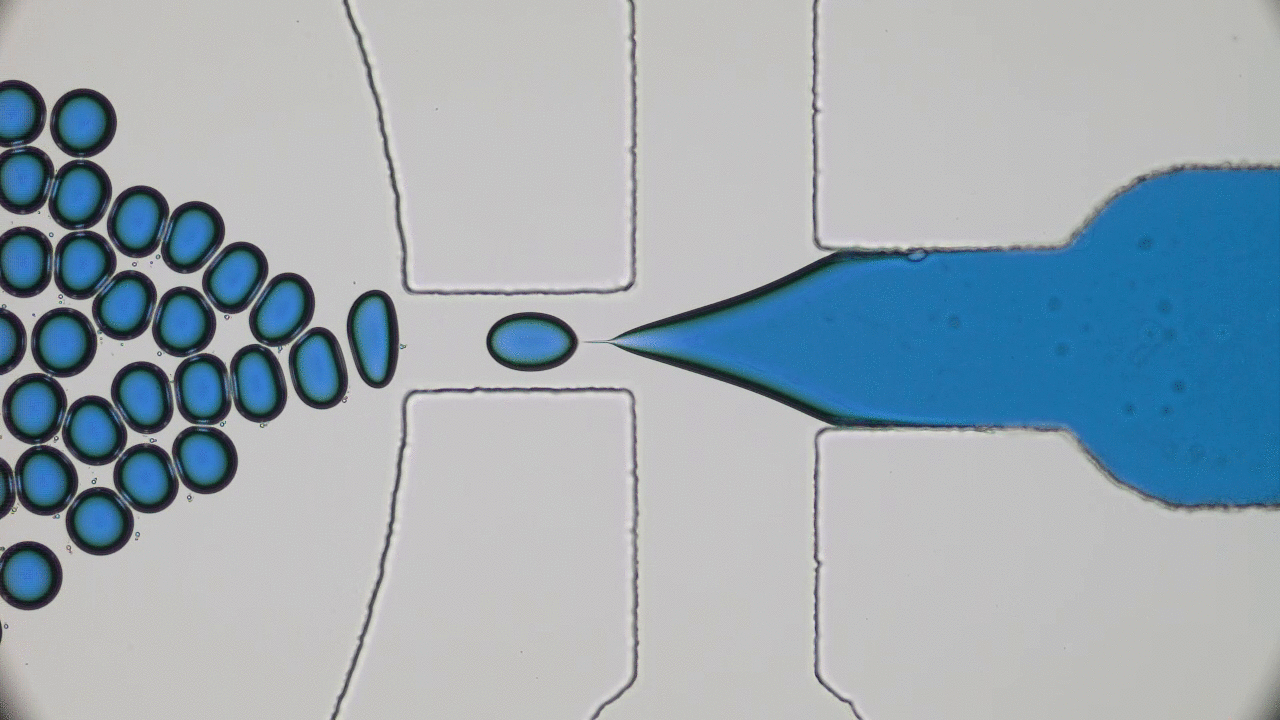
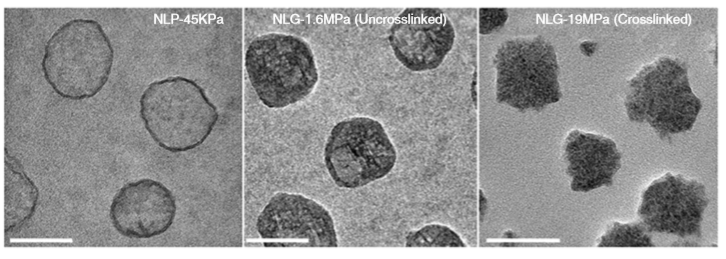
So what are nanolipogels? This type of nanoparticles is basically an altered version of a nanoliposome, a particle-like object that consists of a liquid water core surrounded by a layer of phospholipid molecules [1]. Guo and his colleagues created nanolipogels by filling the nanoliposomes’ liquid core with a polymer of tunable chemical structure. Nanolipogels have precise size (160 nm) and shape (spherical), and their elasticity can be made to vary without changing their other properties (see Figure 1).
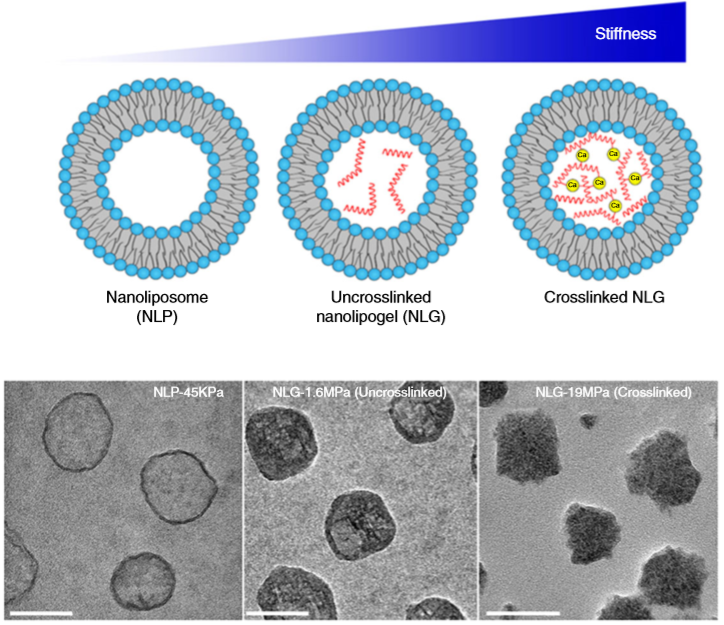
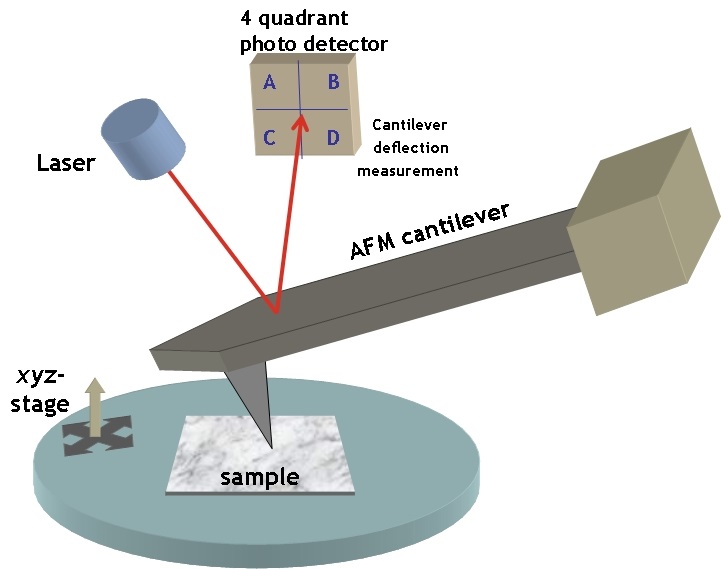
To measure the elasticity of the particles they had produced, Guo and coworkers used a technique called Atomic Force Microscopy (AFM). AFM is commonly used to visualize soft materials by imaging the height of their surface through the deflection of a cantilever (Figure 2). In this paper, the researchers used AFM for a different purpose: to calculate the Young’s modulus — a measure of stiffness — of the nanoparticles. They did this by compressing the particles between the cantilever tip and a solid surface, allowing the researchers to measure the force required to deform the particles by some known amount. The relationship between the applied force, the degree of deformation, and the Young’s modulus is given by the Hertz equation [2]. What you need to remember is that the greater the modulus, the stiffer the particle.
The researchers created four different nanolipogels of different elasticity with Young’s moduli ranging from 1.6 MPa (roughly the stiffness of cork) to 19 MPa (the stiffness of leather), and a nanoliposome without polymer in the core with a Young’s modulus at 0.045 MPa (roughly the stiffness of gummy bears). After verifying that all 5 particles could successfully encapsulate drug molecules, they tested how well tumor cells could uptake each particle. To do so, they used breast cancer cells in the lab (in vitro cellular uptake) and attached fluorescent dye to the particles to determine whether they were inside or outside of the cells. They found that the stiffest nanolipogels were 80% less effective compared to the softest nanoliposome samples; in other words, five times more of the softer particles got inside the cells. In vivo tumor uptake studies, using live mice, similarly showed that the nanoliposomes had up to 2.6 times higher cellular uptake than the stiffest nanolipogels.
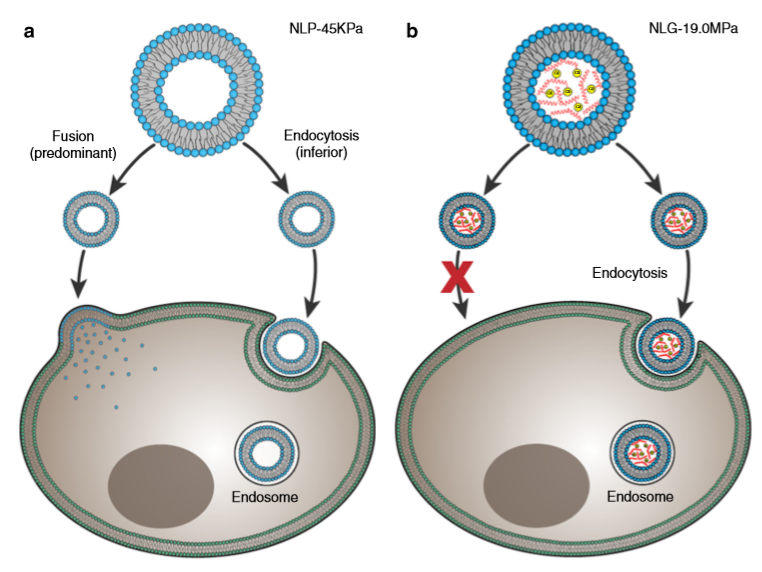
Why do the soft nanoliposomes enter the cells more easily? To understand the conclusion of Guo and colleagues, we need to think about how nano-objects enter a cell. Figure 3 shows two possible ways of doing this: 1. fusion, where nano-objects break up and join the cell membrane, or 2. endocytosis, where the whole object enters the cell by bending the cell’s membrane and getting covered in a membrane outer layer. Fusion needs less energy compared to endocytosis, where cell membrane bending and surface tension increase the energy. The researchers hypothesized that nanoliposomes use both fusion and endocytosis, with a preference for fusion (Figure 3a), while nanolipogels can only enter the cell through endocytosis (Figure 3b). This hypothesis was verified by using chemical compounds that prevented endocytosis from taking place; in all experiments, the cellular uptake of nanoliposomes was as high as before, while much fewer nanolipogels were detected in the cells, since they couldn’t enter through endocytosis.
This study showed that a nanoparticle’s mechanical property, in particular, its elasticity, affects how it enters cells, a finding that could potentially have a tremendous impact on cancer treatment and diagnosis. The use of nanoliposomes, which are a synthetic equivalent of nature’s drug delivery systems, may also be used in the future to further understand how cellular processes, such as fusion and endocytosis, take place.
[1] Phospholipids are surfactants commonly present in cell membranes. This type of lipids consists of a hydrophilic head and two hydrophobic tails that tend to sit at the interface between oil and water.
[2] The Hertz equation is $latex F=\frac{E}{1-\nu} \frac{\tan\beta}{\sqrt2}\delta^2$, where F is the measured force, E is the Young’s modulus, ? is the face angle, ? is the Poisson’s ratio of the material (assumed here to be 0.5), and ? is the surfaces indentation depth.