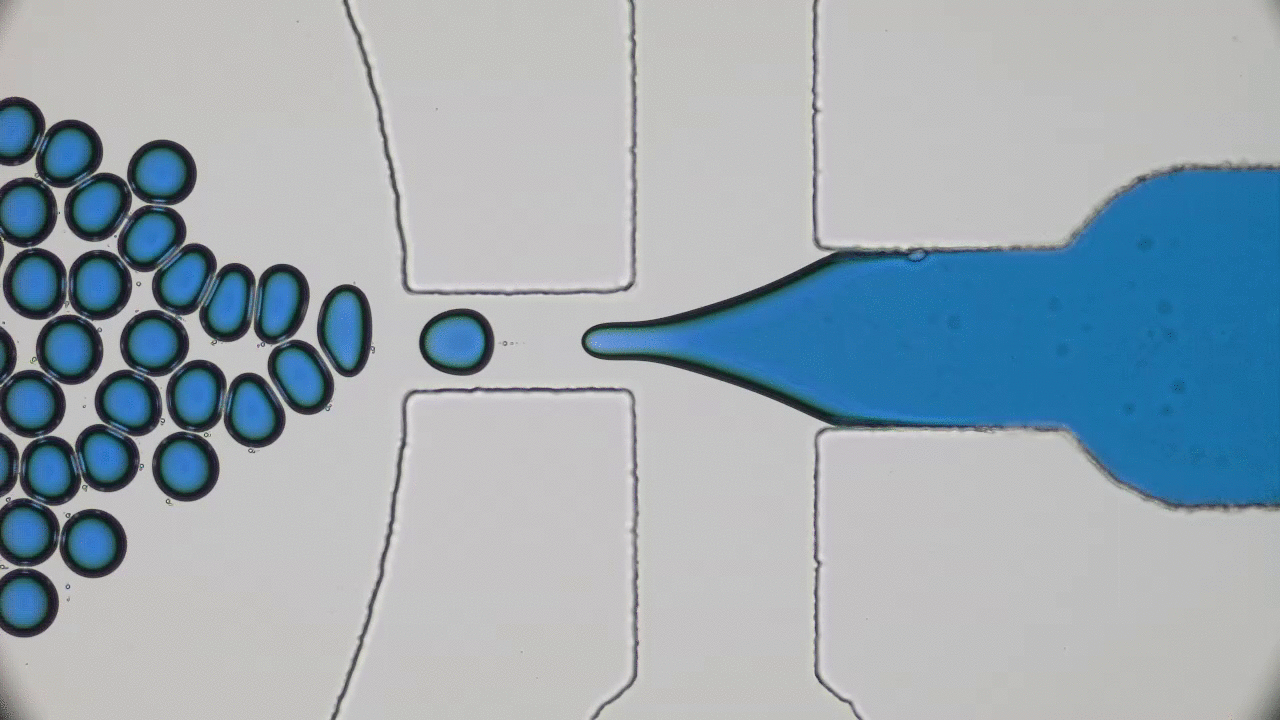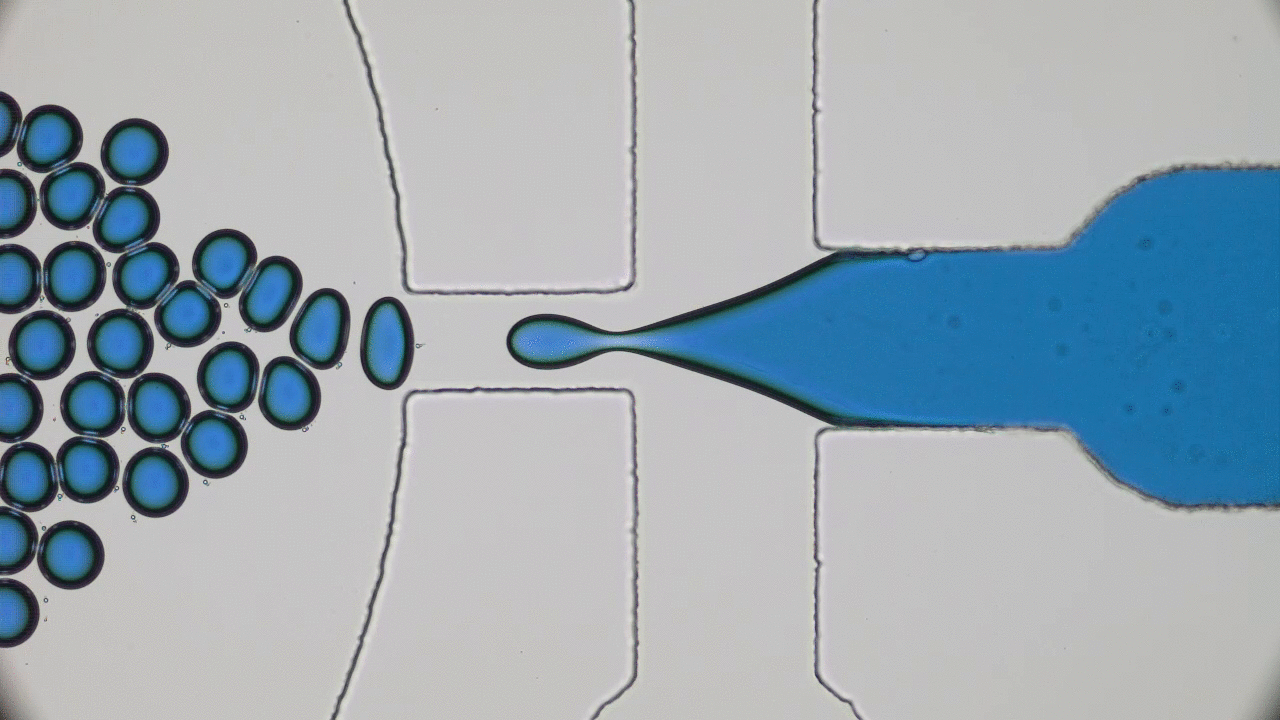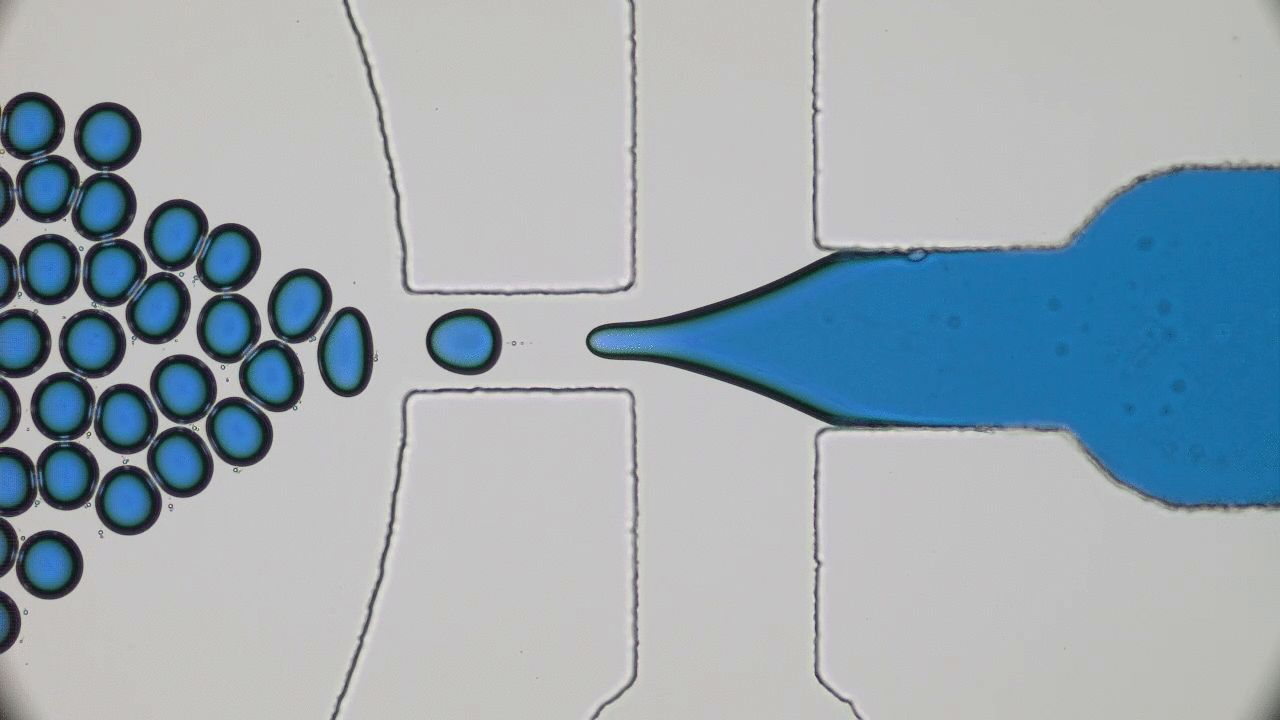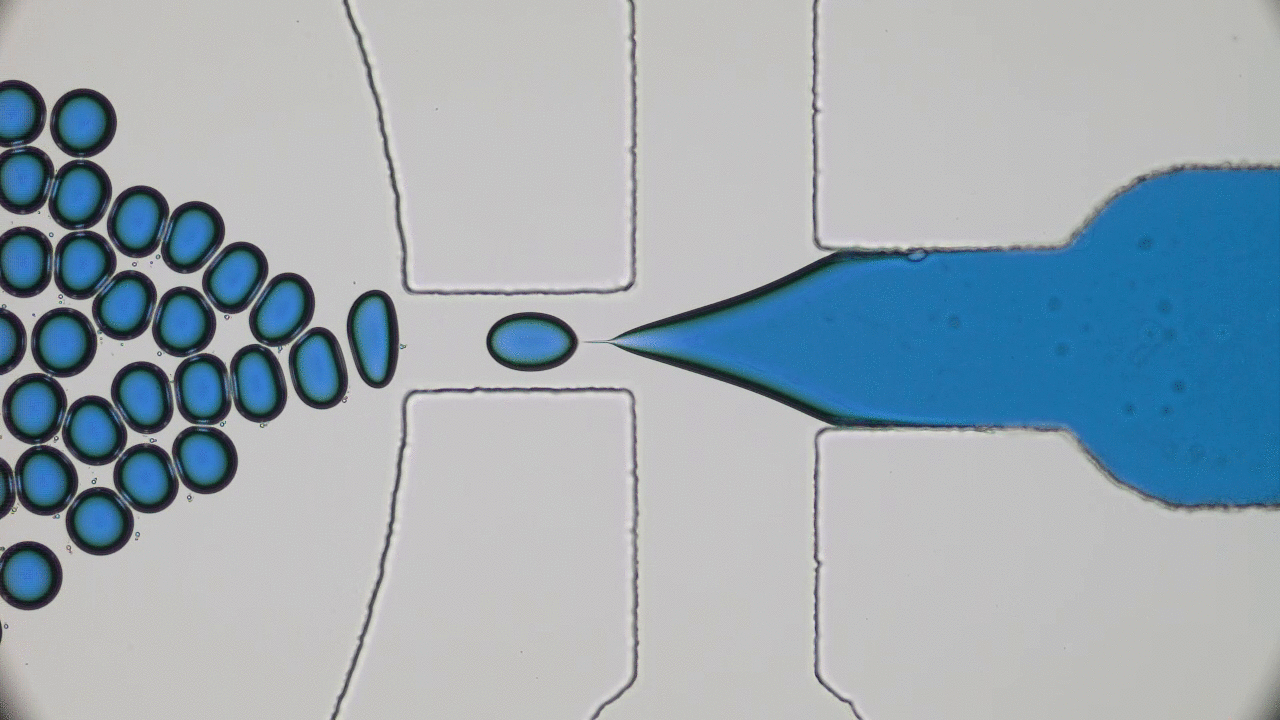

I was ready. I was so ready. I had all my chargers and AV adapters. My presentation was backed up on a USB drive. I had every talk I wanted to go to on my calendar. I had sent emails to professors I wanted to meet and network with. I reached out to friends I only see in March in a different city every year. It was 10 pm on Saturday, February 29. My flight to Denver was leaving at 6 am in the morning. Then the email arrived —
APS March Meeting self-organizes online





